뒤로가기
AI 기술 발전을 기다리며 자산을 쌓는 중
디자인 생산성을 높여보려고 Claude Code를 꽤 적극적으로 실험해봤어요. 결론부터 말하자면, 텍스트와 파일 처리에 최적화된 에이전트에게 시각 정보 중심의 디자인을 완성도 있게 맡기는 건 단기적으로는 효율이 떨어진다는 판단이 들었어요.
그렇다고 손 놓고 있긴 아쉬웠고 텍스트 기반 LLM의 한계를 넘어서는 기술과 제품이 나올 때까지, 디자인 자산을 AI 친화적으로 쌓아두며 준비하는 게 효율적이라는 생각이에요. 그래서 최근에 사고를 발산하는 단계를 도와주는 피그마 플러그인을 만들었어요. 이름은 imweb-mobbin. Mobbin을 오마주했어요. 당연히 클로드 코드와 함께 만들었죠.
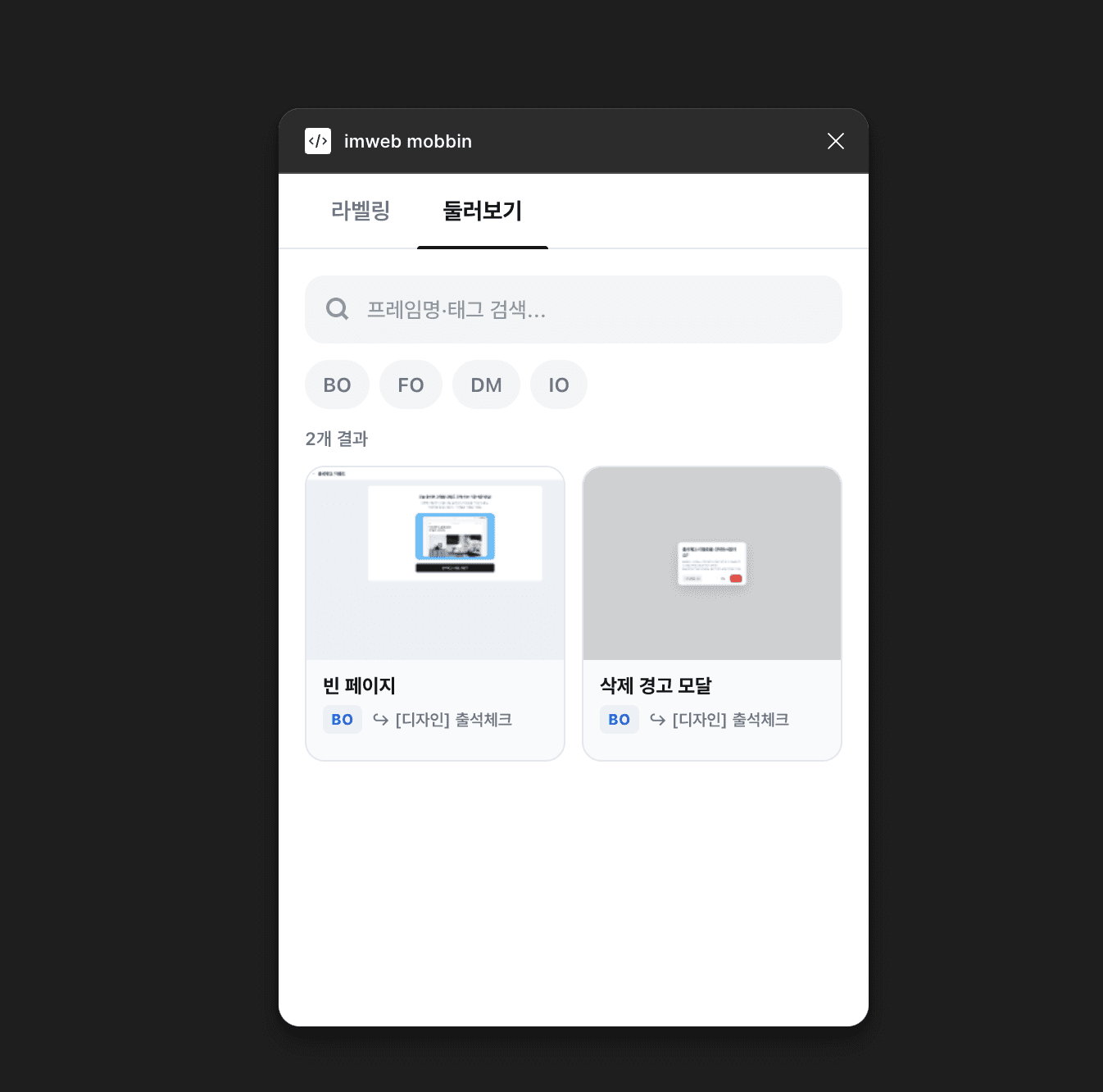
디자인 챕터원들은 각자 스쿼드에 속해 일하다 보니, 결국 비슷한 디자인 문제를 따로따로 고민하게 되는 순간들이 있어요. 물론 매주 서로의 작업을 공유하긴 합니다. 그럼에도 '지금 내가 고민하는 이 화면, 다른 디자이너가 이미 풀어둔 게 있지 않을까?', '우리 제품 어딘가에 비슷한 패턴이 이미 있지 않을까?' 같은 고민을 하곤 하는데요. 그때마다 여러 피그마 파일을 열었다 닫았다 반복하고 있었고, 저는 그 탐색 시간을 줄이고 싶었어요.
처음에는 Frame 단위로 맥락을 수동으로 라벨링하는 방식이었어요. 속도보다 정확성이 우선이라고 생각했거든요. UI 요소인지, Flow인지, UX 패턴인지 사람이 직접 판단해서 붙이는 구조였죠. 검색이라는 게 결국 이름이 아니라 맥락으로 이뤄져야 쓸만하다고 봤거든요.
근데 100개 정도 쌓다 보니 지속 가능하지 않겠더라고요. 그래서 최근에 AI가 화면을 UI 패턴과 UX 의도를 추론해서 자동으로 등록해주는 구조로 바꿨어요. 이런 것을 few-shot 이라고 하나요? 사람이 쌓아둔 라벨을 AI가 학습하고 그 기준에 맞춰 새 화면의 맥락을 추론합니다. 검색도 단순 키워드에서 semantic search 기반으로 다시 설계했어요. 단어가 정확히 일치하지 않아도 의미로 찾을 수 있게요.
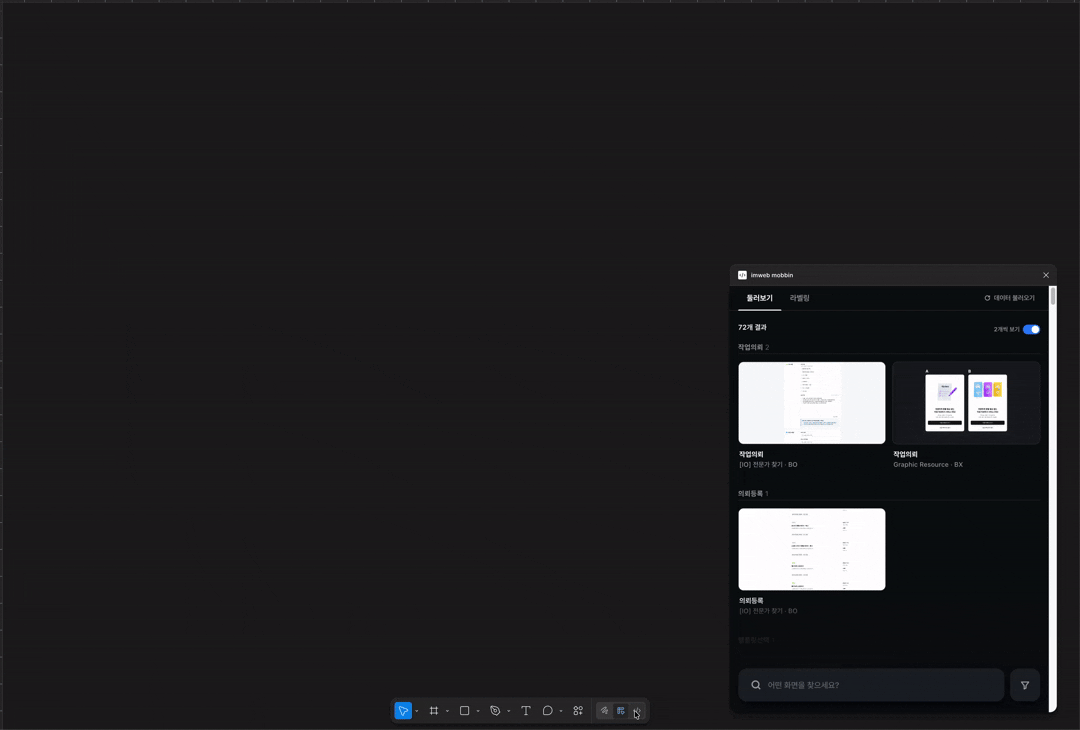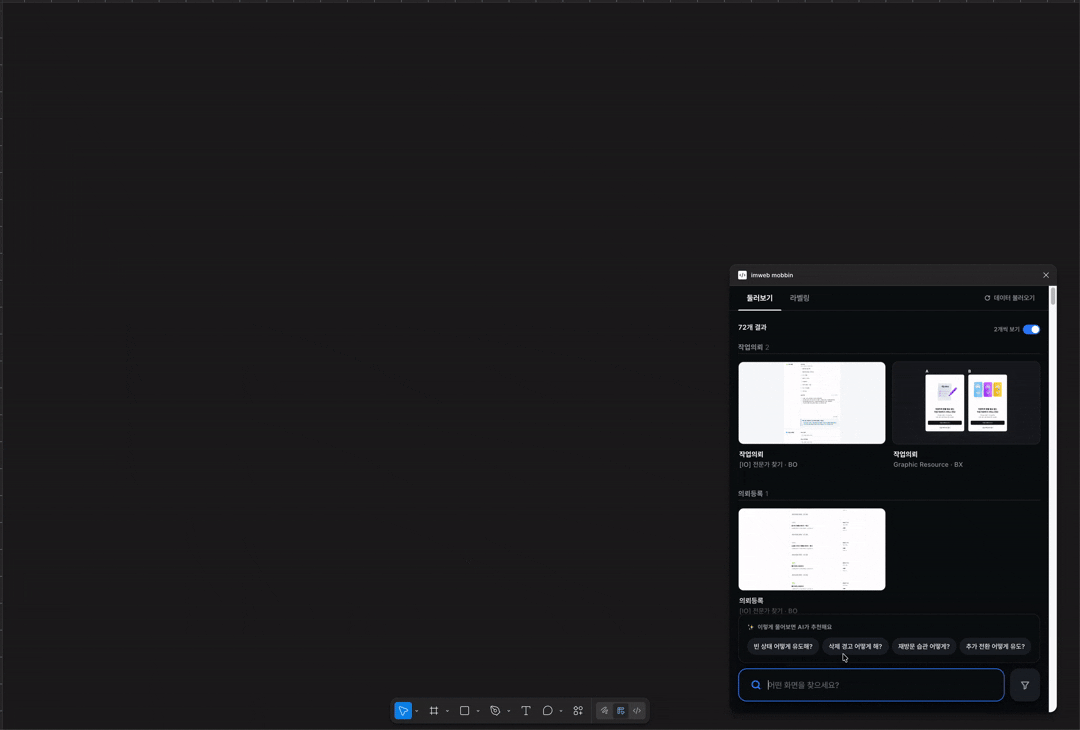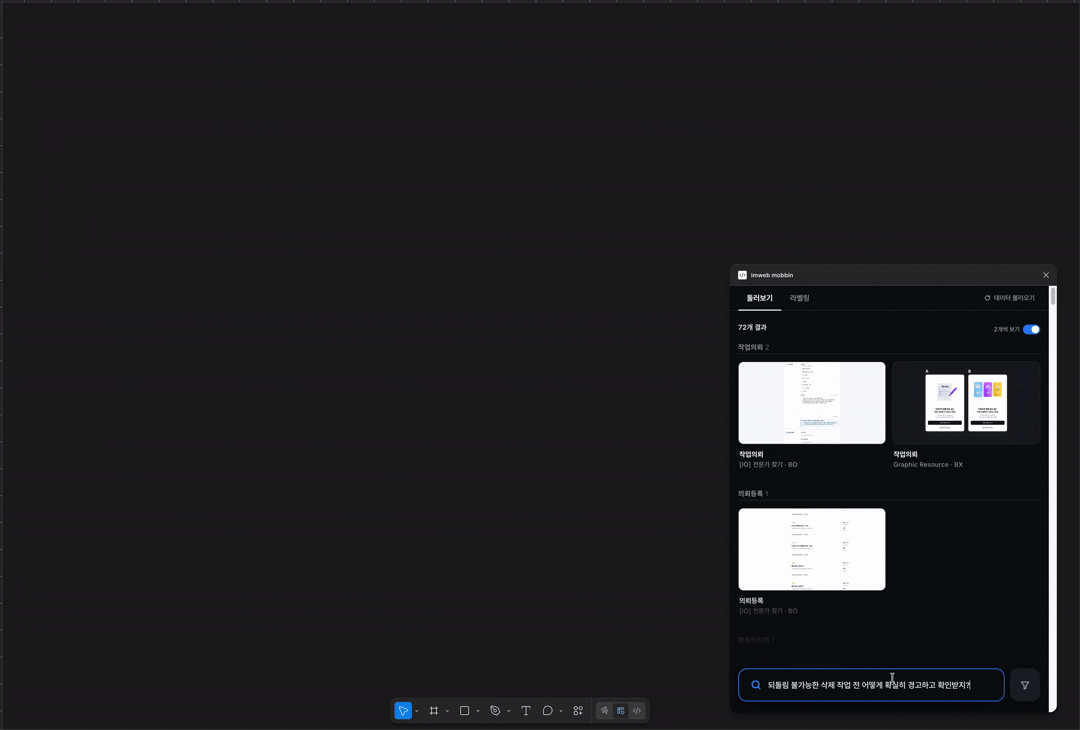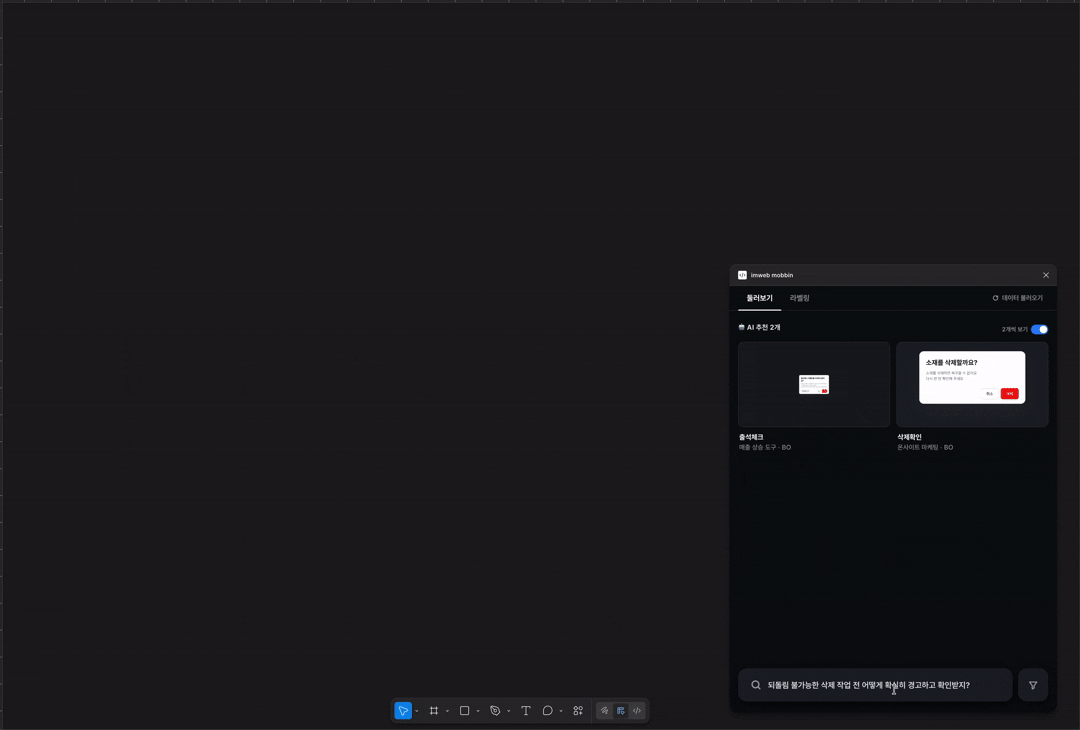
화면 추론과 검색을 위해 Opus, Sonnet 등 여러 모델을 비교 테스트했어요. 태스크마다 적합한 모델이 달라서, 추론이 필요한 구간과 요약이 필요한 구간을 나눠서 붙였고요. Semantic search에는 Voyage AI 임베딩 서비스도 붙여봤어요.
Google Apps Script와 Google Sheets로 관리하고, 내부용 플러그인이라 피그마 커뮤니티에 올리지 않고, 최초 manifest 파일만 공유되면 팀원들이 각자 업데이트를 pull 받을 수 있도록 배포 구조를 설계했어요. 사내에서 쓰는 도구라 이 방식이 훨씬 가볍더라고요.
제가 지금 하는 일의 근본적인 이유는 Anthropic, OpenAI 같은 빅테크의 기술을 기다리면서, 기존 회사가 가진 고유한 자산을 데이터화해두는 것입니다. 새로운 기술이 나왔을 때 곧바로 적용할 수 있게요.
사실 처음에는 이것저것 직접 만들고 실험해봤는데요. 아직 그들의 기술력, 속도, 완성도를 개인이나 작은 팀이 따라가는 건 어렵고 비효율이라는 판단이 들었어요. 그래서 지금은 '새 기술이 나오는 순간 쓸모가 생기는 자산'을 쌓는 데 집중하고 있어요.
빅테크의 의존도가 높다 보니 준비하는 쪽이 효율이라고 생각했어요.
솔직히 데이터 라벨링도, 구조 설계도 노가다에 가까운 일이긴 한데요. 다만 이 데이터가 Claude 같은 에이전트와 결합되는 순간, 꽤 무서운 자산이 될 거라고 믿고 있어요.
글을 보면서 혹시 느끼셨나요? 과거의 저에게 절대 나올 수 없는 용어들이 난무하고 있는데요. 디자이너의 문제 해결은 무엇을 어떻게 해결할지 정말 감이 안 오는 요즘입니다.